Conducting polls on Twitter suffers a similar problem: instead of a physical Yankee Stadium, we can imagine Twitter followers as a virtual community of people with similar views or interests. Imagine the Twitter following of Bill Bishop, for example, author of the leading China-focused newsletter Sinocism. Much like his newsletter, Bill’s followers likely fit a fairly similar profile: generally better educated, disproportionately concentrated in metropolitan areas (e.g., Washington DC, New York, London) and, above all, keenly interested in all things China.
If Bill were to field a Twitter poll right now asking respondents whether they’re interested in Chinese politics, we would expect most people to say ‘Yes, I am interested’. Similarly, if we polled only his paid newsletters subscribers, we’d expect this number to approach 100%.
In technical terms, Twitter polls are biased by their non-representative sample frames (in this case, the followers of the Twitter account fielding the poll). In professional polls, specialized methods are employed to ensure that the sampling frame approaches the characteristics of the population of interest. For example, some pollsters use a method called random digit dialing to approximate a random sample of the United States population.
Even methods used by experts are not a panacea, however, which brings us to the second problem with Twitter polls.
Problem #2: We cannot make claims about margin of error.
Suppose you’re trying to survey the population of China about their opinion on the United Nations. If we are going to use a sample of Chinese citizens to make a claim about Chinese public opinion, we need to make sure that the sample actually looks like the Chinese population. How does one achieve this?
In an impossibly perfect world, you’d compile a list of every Chinese citizen and then randomly select a few thousand of them and ask for their opinion. The reasoning behind random selection here is that every citizen would have an equal probability of being chosen for the survey regardless of their individual traits, such as their age, gender, education, income, and so on. Although it would be too arduous and expensive to survey everyone, statisticians have demonstrated how drawing randomly from a population produces a sample that gradually resembles the population of interest.
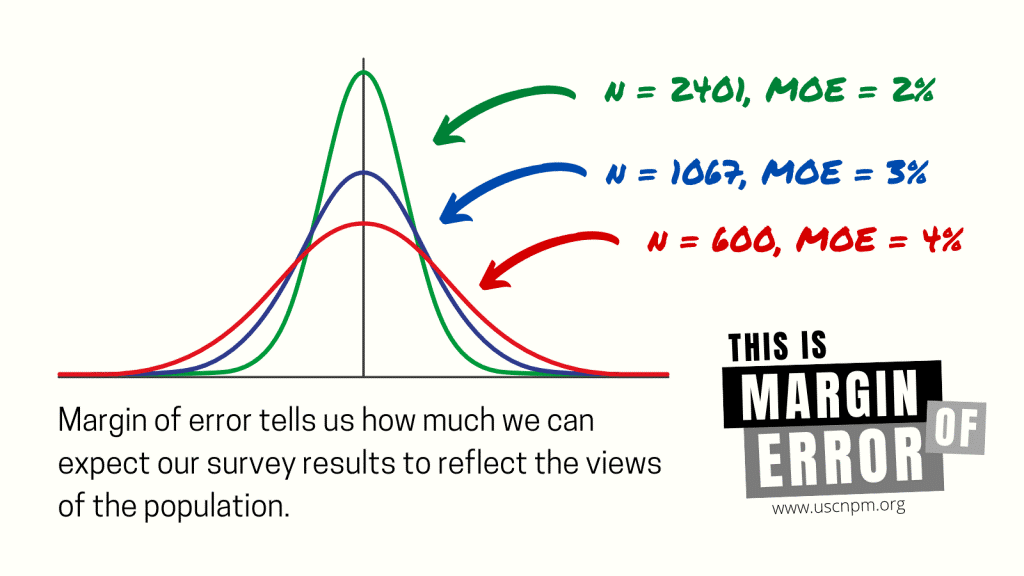
This allows us to calculate the margin of error, or the range of values that we’d feel confident the true population falls in. As a random sample gets larger, the margin of error gets smaller.